By admin on Oct 16, 2008 | In C/C++, open source | No Comments »
Sphinx is a full-text search engine. It is a standalone search engine, meant to provide fast, size-efficient and relevant full-text search functions to other applications. Sphinx was specially designed to integrate well with SQL databases and scripting languages.
Currently built-in data source drivers support fetching data either via direct connection to MySQL, or PostgreSQL, or from a pipe in a custom XML format. Adding new drivers (eg. to natively support some other DBMSes) is designed to be as easy as possible.
Search API is natively ported to PHP, Python, Perl, Ruby, Java, and also available as a pluggable MySQL storage engine. API is very lightweight so porting it to new language is known to take a few hours.
It features
- high indexing speed (upto 10 MB/sec on modern CPUs)
- high search speed (avg query is under 0.1 sec on 2-4 GB text collections)
- high scalability (upto 100 GB of text, upto 100 M documents on a single CPU)
- supports distributed searching (since v.0.9.6)
- supports MySQL natively (MyISAM and InnoDB tables are both supported)
- supports phrase searching
- supports phrase proximity ranking, providing good relevance
- supports English and Russian stemming
- supports any number of document fields (weights can be changed on the fly)
- supports document groups
- supports stopwords
- supports different search modes (“match all”, “match phrase” and “match any” as of v.0.9.5)
- generic XML interface which greatly simplifies custom integration
- pure-PHP (ie. NO module compiling etc) search client API
Currently known systems Sphinx has been successfully running on are:
- Linux 2.4.x, 2.6.x (various distributions)
- Windows 2000, XP
- FreeBSD 4.x, 5.x, 6.x
- NetBSD 1.6, 3.0
- Solaris 9, 11
- Mac OS X
Popularity: 2% [?]
By admin on Oct 16, 2008 | In C/C++, open source | 2 Comments
libevent is an event notification library. It provides a mechanism to execute a callback function when a specific event occurs on a file descriptor or after a timeout has been reached. Furthermore, libevent also support callbacks due to signals or regular timeouts.
libevent is meant to replace the event loop found in event driven network servers. An application just needs to call event_dispatch()and then add or remove events dynamically without having to change the event loop.
Currently, libevent supports /dev/poll, kqueue(2), event ports, select(2), poll(2) and epoll(4). The internal event mechanism is completely independent of the exposed event API, and a simple update of libevent can provide new functionality without having to redesign the applications. As a result, Libevent allows for portable application development and provides the most scalable event notification mechanism available on an operating system. Libevent can also be used for multi-threaded applications. Libevent should compile on Linux, *BSD, Mac OS X, Solaris and Windows.
More information about event notification mechanisms for network servers can be found on Dan Kegel’s “The C10K problem” web page. Another library that abstracts asynchronous event notification is liboop.
Popularity: 2% [?]
By admin on Oct 16, 2008 | In freebies, windows | No Comments »
The Web Platform Installer Beta (Web PI) provides a single, free package for installing and configuring Microsoft’s entire Web Platform, including IIS7, Visual Web Developer 2008 Express Edition, SQL Server 2008 Express Edition and the .NET Framework. Using the Web Platform Installer’s simple user interface, you can select specific components or install the entire Microsoft Web Platform onto your computer. To help you stay up-to-date with product releases, the Web Platform Installer always contains the most current versions and new additions to the Microsoft Web Platform.
Requirements
- Supported Operating Systems are: Windows Vista RTM, Windows Vista SP1, Windows Server 2008
- You must have administrator privileges on your computer to run Web Platform Installer Beta
- .NET 2.0 Framework
- Supported Architectures: x86 and 64-bit
Popularity: 1% [?]
By admin on Oct 15, 2008 | In Java, open source | No Comments »
As quoted from Wikipedia, an XML database is a data persistence software system that allows data to be stored in XML format. This data can then be queried, exported and serialized into any format the developer wishes.
Two major classes of XML database exist:
- XML-enabled: these map all XML to a traditional database (such as a relational database), accepting XML as input and rendering XML as output. This term implies that the database does the conversion itself (as opposed to relying on middleware).
- Native XML (NXD): the internal model of such databases depends on XML and uses XML documents as the fundamental unit of storage, which are, however, not necessarily stored in the form of text files.
Here are some open source XML database
eXist-db
eXist-db is an open source database management system entirely built on XML technology. It stores XML data according to the XML data model and features efficient, index-based XQuery processing.
eXist-db supports many (web) technology standards making it an excellent application platform:
Sedna
Sedna is a free native XML database designed to be a universal system for a wide range of XML applications such as content management, event-based SOA, etc. Sedna is a full-featured database system that provides a full range of core database services (such as transactional store and recovery) and flexible XML processing via the W3C-standard XQuery language.
- Load XML data “AS IS” with no need to adhere to any predefined schema
- Support for large (hundreds of GBs) databases
- Powerful processing facilities: XQuery, Updates, Full-text search, Integration with SQL databases, etc
- Easy to run and use
Oracle Berkeley DB XML
Oracle Berkeley DB XML is an open source, embeddable XML database with XQuery-based access to documents stored in containers and indexed based on their content. Oracle Berkeley DB XML is built on top of Oracle Berkeley DB and inherits its rich features and attributes. Like Oracle Berkeley DB, it runs in process with the application with no need for human administration. Oracle Berkeley DB XML adds a document parser, XML indexer and XQuery engine on top of Oracle Berkeley DB to enable the fastest, most efficient retrieval of data.

Benefits
- High Performance—fast XML data storage and retrieval using W3C standard XQuery and XPath
- Rich Features—built on top of Oracle Berkeley DB, inheriting all its features such as transactions and replication
- Zero Administration—applications perform database administration, eliminating the need for a DBA and allowing continuous, unattended operation
- Low TCO—extreme performance reduces hardware costs and being embedded eliminates DBA costs
Apache Xindice
Apache Xindice is a database designed from the ground up to store XML data or what is more commonly referred to as a native XML database.
dbXML
dbXML is a Native XML Database. It is capable of storing and indexing collections of XML documents in both native and mapped forms for highly efficient querying, transformation, and retrieval. In addition to these capabilities, the server may also be extended to provide business logic in the form of scripts, classes and triggers.
Some good references for reading
- http://www.rpbourret.com/xml/
- minx is an open-source project to create a generic XML repository architecture for common relational database management systems which avoids using any proprietary XML extensions.
Popularity: 2% [?]
By admin on Oct 14, 2008 | In Java, Programming | 4 Comments
Here is a simple JSON utility class that I used to do the followings
- Convert JSON string to a Map and vice versa
- Convert JSON string to list of maps and vice versa
This class encapsulate all the JSON string manipulation in a single Java class so that it frees you up from the actual JSON implementation. You can replace the JSON library just by changing this class later if needed.
You can download the source code here.
Here is the sample code snippet for testing
1: /**
2: * Test Stub
3: *
4: * @param args
5: */
6: public static void main(String[] args) {
7: Map<String, String> map = new HashMap<String, String>();
8: map.put("name", "jason");
9: map.put("email", "[email protected]");
10:
11: // Convert map to JSON string
12: String jsonString = JsonUtil.getJsonStringFromMap(map);
13: System.out.println(jsonString);
14:
15: // Convert Json string to map
16: Map<String, String> newMap = JsonUtil.getMapFromJsonString(jsonString);
17: System.out.println(newMap);
18:
19:
20: Map<String, String> anotherMap = new HashMap<String, String>();
21: anotherMap.put("name", "alice");
22: anotherMap.put("email", "[email protected]");
23:
24: List<Map<String, String>> mapList = new ArrayList<Map<String, String>>();
25: mapList.add(map);
26: mapList.add(anotherMap);
27: // Convert to json string
28: jsonString = JsonUtil.getJsonStringFromList(mapList);
29: System.out.println(jsonString);
30:
31: // Convert Json string to list of map
32: List<Map<String, String>> newMapList = JsonUtil.getListFromJsonArray(jsonString);
33: System.out.println(newMapList);
34:
35:
36: }
The output
The code uses the Jackson JSON library.
Popularity: 4% [?]
By admin on Oct 14, 2008 | In open source | No Comments »
Future versions of Firefox plan on supporting the new W3C Geolocation Specification, which adds the native ability for Web sites to request, and you to optionally grant access to, your location.

Geode is an experimental add-on to explore geolocation in Firefox 3 ahead of the implementation of geolocation in a future product release. Geode provides an early implementation of the W3C Geolocation specification so that developers can begin experimenting with enabling location-aware experiences using Firefox 3
Popularity: 1% [?]
By admin on Oct 13, 2008 | In open source | No Comments »
Kino is a non-linear DV editor for GNU/Linux. It features excellent integration with IEEE-1394 for capture, VTR control, and recording back to the camera. It captures video to disk in Raw DV and AVI format, in both type-1 DV and type-2 DV (separate audio stream) encodings.

You can load multiple video clips, cut and paste portions of video/audio, and save it to an edit decision list (SMIL XML format). Most edit and navigation commands are mapped to equivalent vi key commands. Also, Kino can export the composite movie in a number of formats: DV over IEEE 1394, Raw DV, DV AVI, still frames, WAV, MP3, Ogg Vorbis, MPEG-1, MPEG-2, and MPEG-4. Still frame import and export uses gdk-pixbuf, which has support for BMG, GIF, JPEG, PNG, PPM, SVG, Targa, TIFF, and XPM. MP3 requires lame. Ogg Vorbis requires oggenc. MPEG-1 and MPEG-2 require mjpegtools or ffmpeg. MPEG-4 requires ffmpeg.
General
- Free Software (GNU GPL)
- GTK+ 2.0 UI
- XML SMIL 2.0 project file format
- OSS or ALSA audio playback
- GDK or XVideo video playback
- online help
- Peer and developer support forums
- User interface translated to Danish, Swedish, French, Czech, Spanish, Russian, Italian, German, Hungarian, and Norwegian.
- Extensible project metadata system.
- Ability to “publish” project file and still frames using an extensible scripting interface.
- Integrated publishing to the http://blip.tv/ web video sharing site
Media Support
- DV-based (libdv and ffmpeg DV codecs)
- PAL or NTSC
- AVI (type1 or type2) or Raw DV files. with large AVI (OpenDML) and LFS (>2GB) support
- Optionally, Quicktime DV format
Popularity: 1% [?]
By admin on Oct 13, 2008 | In hacking, windows | 2 Comments
Light Logger is a monitoring software that allows you to keep track of what is happening on your computer. This spy software runs hidden in the background, and automatically logs all keystrokes. Light Logger monitoring software starts at a low level that allow you to make logging even when an anti-keylogger is installed.
It features:
- Absolutely free.
- Easy to install and using.
- Logs all keystrokes, is case sensitive (keystroke logger).
- Multi-language support.
- All the information is stored in the log file including system passwords, ICQ, MSN, Yahoo, IAM, Skype messages and e-mail clients.
- Generates the report in the html format.
- The password fields are shown with the picture

- Support special characters like [BACK], [CTRL], [DEL] and others.
- Small size 170Kb.
Popularity: 3% [?]
By admin on Oct 12, 2008 | In Java, open source | 1 Comment »
Grizzly is a Java NIO frameowork to help developers to build scalable and robust servers using NIO. It offers embeddable components supporting HTTP, Bayeux Protocol, Servlet (Partially) and Comet.
It is similar to other frameworks like Apache Mina. Using it you can easily build scalable server applications in the Java.
Popularity: 1% [?]
By admin on Oct 11, 2008 | In open source | No Comments »
OpenMRS is a community-developed, open-source, enterprise electronic medical record system framework.
It is formed in 2004 as a open source medical record system framework for developing countries — a tide which rises all ships. OpenMRS is a multi-institution, nonprofit collaborative led by Regenstrief Institute, Inc. (http://regenstrief.org), a world-renowned leader in medical informatics research, and Partners In Health (http://pih.org), a Boston-based philanthropic organization with a focus on improving the lives of underprivileged people worldwide through health care service and advocacy.
OpenMRS has been implemented in several African countries, including South Africa, Kenya, Rwanda, Lesotho, Zimbabwe, Mozambique, Uganda, and Tanzania. This work is supported in part by organizations such as the World Health Organization (WHO), the Centers for Disease Control (CDC), The Rockefeller Foundation, and the President’s Emergency Plan for AIDS Relief (PEPFAR).
Popularity: 1% [?]
By admin on Oct 11, 2008 | In open source | No Comments »
OpenLayers is a pure JavaScript library for displaying map data in most modern web browsers, with no server-side dependencies. OpenLayers implements a JavaScript API for building rich web-based geographic applications, similar to the Google Maps and MSN Virtual Earth APIs, with one important difference — OpenLayers is Free Software, developed for and by the Open Source software community.
Furthermore, OpenLayers implements industry-standard methods for geographic data access, such as the OpenGIS Consortium’s Web Mapping Service (WMS) and Web Feature Service (WFS) protocols. Under the hood, OpenLayers is written in object-oriented JavaScript, using components from Prototype.js and the Rico library. The OpenLayers code base already has hundreds of unit tests, via the Test.AnotherWay framework.
Popularity: 1% [?]
By admin on Oct 11, 2008 | In Java, open source | No Comments »
Here are some open source library for Java byte code manipulation
ASM is an all purpose Java bytecode manipulation and analysis framework. It can be used to modify existing classes or dynamically generate classes, directly in binary form. Provided common transformations and analysis algorithms allow to easily assemble custom complex transformations and code analysis tools.
The ASM bytecode manipulation framework has been designed and implemented to be small and as fast as possible. ASM’s runtime .jar is only 25KB, compared to 350KB for BCEL. The load time overhead caused by class transformation with ASM is about 60 percent with ASM, compared to 700 percent or more with BCEL. These factors have been recognized by the Java community and several well known projects have switched to ASM, such as CGLIB and AspectWerkz. The list of projects that are using form the beginning ASM also includes Speedo, Groovy, dynaop,BeanShell, and a number of others.
The Byte Code Engineering Library is intended to give users a convenient possibility to analyze, create, and manipulate (binary) Java class files (those ending with .class). Classes are represented by objects which contain all the symbolic information of the given class: methods, fields and byte code instructions, in particular. However, the library is not being updated for long time.
Javassist (Java Programming Assistant) makes Java bytecode manipulation simple. It is a class library for editing bytecodes in Java; it enables Java programs to define a new class at runtime and to modify a class file when the JVM loads it. Unlike other similar bytecode editors, Javassist provides two levels of API: source level and bytecode level. If the users use the source-level API, they can edit a class file without knowledge of the specifications of the Java bytecode. The whole API is designed with only the vocabulary of the Java language. You can even specify inserted bytecode in the form of source text; Javassist compiles it on the fly. On the other hand, the bytecode-level API allows the users to directly edit a class file as other editors.
cglib is a powerful, high performance and quality Code Generation Library, It is used to extend JAVA classes and implements interfaces at runtime. It is used by Hibernate, Spring, iBatis and other software.
Popularity: 1% [?]
By admin on Oct 11, 2008 | In Good Reading, Java | No Comments »
The Java Platform, Standard Edition (Java SE platform) 6 features utilities that allow you to monitor and manage the performance of a Java Virtual Machine (Java VM) and the Java applications that are running in it.
The Java SE Monitoring and Management Guide describes those monitoring and management utilities.
Popularity: 2% [?]
By admin on Oct 11, 2008 | In open source | No Comments »
I am a user of Facebook, but not as frequent as my friends. But I do find that the open source tools provided or contributed by Facebook interesting.
Facebook has indeed provided some very good open source tools
Popularity: 1% [?]
By admin on Oct 8, 2008 | In open source, windows | No Comments »
InSSIDer is a free Wi-Fi network scanner for Windows Vista and windows XP. It is developed as NetStumbler doesn’t work well with Windows Vista and 64-bit Windows XP.
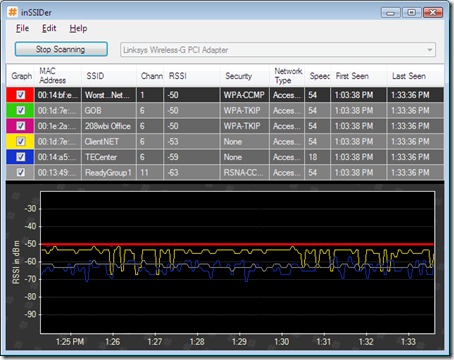
This project was started by Charles Putney on The Code Project. Norman Rasmussen modified the project to use the Managed Wi-Fi C# wrapper for the Native Wi-Fi API.
Popularity: 2% [?]
By admin on Oct 8, 2008 | In Java, Programming | No Comments »
If you need an ordered Map or Set, meaning maintaining the original in your Map or Set in the order you insert or add them, then you should use LinkedHashMap or LinkedHashSet.
Some sample code below.
1: import java.util.*;
2:
3: public class TestClass {
4:
5: public static void main(String[] args) {
6: Map<String, String> unOrdereddMap = new HashMap<String, String>();
7: unOrdereddMap.put("1", "one");
8: unOrdereddMap.put("2", "two");
9: unOrdereddMap.put("3", "three");
10: for (String key : unOrdereddMap.keySet()) {
11: System.out.println(unOrdereddMap.get(key));
12: }
13:
14: Map<String, String> orderedMap = new LinkedHashMap<String, String>();
15: orderedMap.put("1", "one");
16: orderedMap.put("2", "two");
17: orderedMap.put("3", "three");
18: for (String key : orderedMap.keySet()) {
19: System.out.println(orderedMap.get(key));
20: }
21:
22:
23: Set<String> unOrderedSet = new HashSet<String>();
24: unOrderedSet.add("1");
25: unOrderedSet.add("2");
26: unOrderedSet.add("3");
27: for (String value : unOrderedSet)
28: System.out.println(value);
29:
30:
31: Set<String> orderedSet = new LinkedHashSet<String>();
32: orderedSet.add("1");
33: orderedSet.add("2");
34: orderedSet.add("3");
35: for (String value : orderedSet)
36: System.out.println(value);
37:
38:
39: }
40:
41:
42: }
LinkedHashMap and LinkedHashSet iterator follow the insertion order whereas the HashMap and HashSet are not.
The output
1: three
2: two
3: one
4:
5: one
6: two
7: three
8:
9: 3
10: 2
11: 1
12:
13: 1
14: 2
15: 3
Popularity: 4% [?]
By admin on Oct 7, 2008 | In .NET, Enterprise, free ebook | 2 Comments

.NET Enterprise Solutions … Software Engineers on their way to Pluto

.NET Enterprise Solutions … Best Practices for the Connoisseur

.NET Enterprise Solutions … Interoperability for the Connoisseur
Downloadable here
Popularity: 3% [?]
By admin on Oct 7, 2008 | In Java, open source | No Comments »
HamCrest is part of JUnit starting version 4.4.
It provides a library of matcher objects (also known as constraints or predicates) allowing ‘match’ rules to be defined declaratively, to be used in other frameworks. Typical scenarios include testing frameworks, mocking libraries and UI validation rules.
Using HamCrest, in JUnit you can now write assertions like the followings
1: String result = "red";
2: ...
3: assertThat(result, equalTo("red"));
4:
5: assertThat(color, anyOf(is("red"),is("green"),is("yellow")));
Hamcrest has been designed from the outset to integrate with different unit testing frameworks like JUnit 3 and 4 and TestNG.
It can also be used with mock objects frameworks by using adaptors to bridge from the mock objects framework’s concept of a matcher to a Hamcrest matcher.
Popularity: 1% [?]
By admin on Oct 7, 2008 | In Java, open source | No Comments »
The Eclipse Persistence Services Project (EclipseLink) project’s goal is to provide a complete persistence framework that is both comprehensive and universal. It will run in any Java environment and read and write objects to virtually any type of data source, including relational databases, XML, or EIS systems.

EclipseLink will focus on providing leading edge support, including advanced feature extensions, for the dominant persistence standards for each target data source;
- Java Persistence API (JPA) for relational databases,
- Java Architecture for XML Binding (JAXB) for XML,
- J2EE Connector Architecture (JCA) for EIS and other types of legacy systems,
- Service Data Objects (SDO).
Popularity: 1% [?]
By admin on Oct 7, 2008 | In open source | No Comments »
memcached is a high-performance, distributed memory object caching system, generic in nature, but intended for use in speeding up dynamic web applications by alleviating database load.
It is used in large website like Digg, Twitter and Facebook. memcached dropped the database load to almost nothing, yielding faster page load times for users, better resource utilization, and faster access to the databases on a memcache miss.
The memcached server and clients work together to implement one global cache across as many machines as you have. In fact, it’s recommended you run both web nodes (which are typically memory-lite and CPU-hungry) and memcached processes (which are memory-hungry and CPU-lite) on the same machines. This way you’ll save network ports.
The client libraries supports Perl, C, C#, PHP, Python, Java, Ruby, and Postgresql Stored Procedures and Triggers.
Tugela is a memcached derived system that’s slower but slightly more like a database.
Popularity: 1% [?]







