
Combine Crunch and Lucene for Efficient Web Page Indexing
By admin on Oct 13, 2007 in Java, open source, Programming
Developers should be familiar with Lucene. Apache Lucene is a high-performance, full-featured text search engine library written entirely in Java. It is a technology suitable for nearly any application that requires full-text search, especially cross-platform.
In one of my previous projects, I need to consolidate and index web pages from several websites for searching purpose. I wrote my application to craw and index web pages using Lucene. Along the way, I categorized web pages into 3 categories, which are structured , semi-structured and unstructured. I used Lucene to index those unstructured web pages.
The major problem I encountered here is that most web pages are full of unnecessary information which make them hard to index accurately. Web pages can contain advertisments, hyperlinks or other unnecessary information which make them hard to be indexed accurrately. For this I need to write a filter to filter out those unneeded information so that web pages can be indexed properly. However, I found a tool which can help me in this context, which is called Crunch.
Crunch is a web proxy, usable with essentially all web browsers, that performs content extraction (or clutter reduction) from HTML web pages. Crunch includes a flexible plug-in API so that various heuristics can be integrated to act as filters, collectively, to remove non-content and perform content extraction.
Here are some screenshots of Crunch.
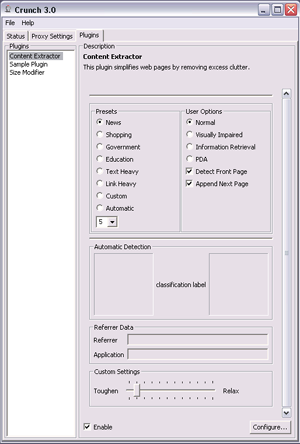
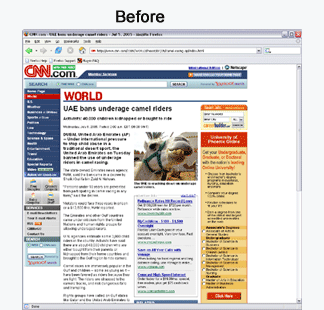
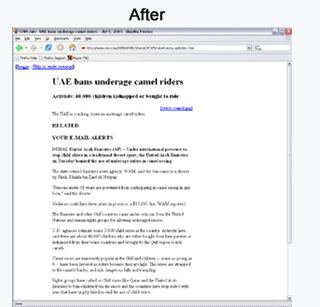
Using Crunch, those web pages to be indexed are first cleaned up, and those non-content are not being indexed. In this way, I was able to use Lucene to index those web pages accurately.
In another article, I will show you how I extract and index content for structured and semi-structured web pages.

3 Trackback(s)
Sorry, comments for this entry are closed at this time.